Alpha Zero Gobang https://github.com/lihongxun945/alpha-zero-gobang
更早的项目AlphaZero_Gomoku https://github.com/junxiaosong/AlphaZero_Gomoku
PS:另一个五子棋的实现 https://github.com/lihongxun945/gobang
AlphaZero_Gomoku原项目使用的Theano过时(最高支持python 3.9),给模型训练带来一些麻烦。pytorch训练的模型并不能直接被正确地加载在该项目的游戏部分。
一个类似的clone https://github.com/Yoda-wu/alpha_zero_feat/tree/main
经过测试可用的clone https://github.com/gingkg/AlphaZero_Gomoku_PyTorch
本人略微修改ui的clone,基于AlphaZero_Gomoku_PyTorch
https://github.com/Farbitrarily/Gonoku
-
自定义了UI界面,修复了Pygame中部分逻辑缺陷。
-
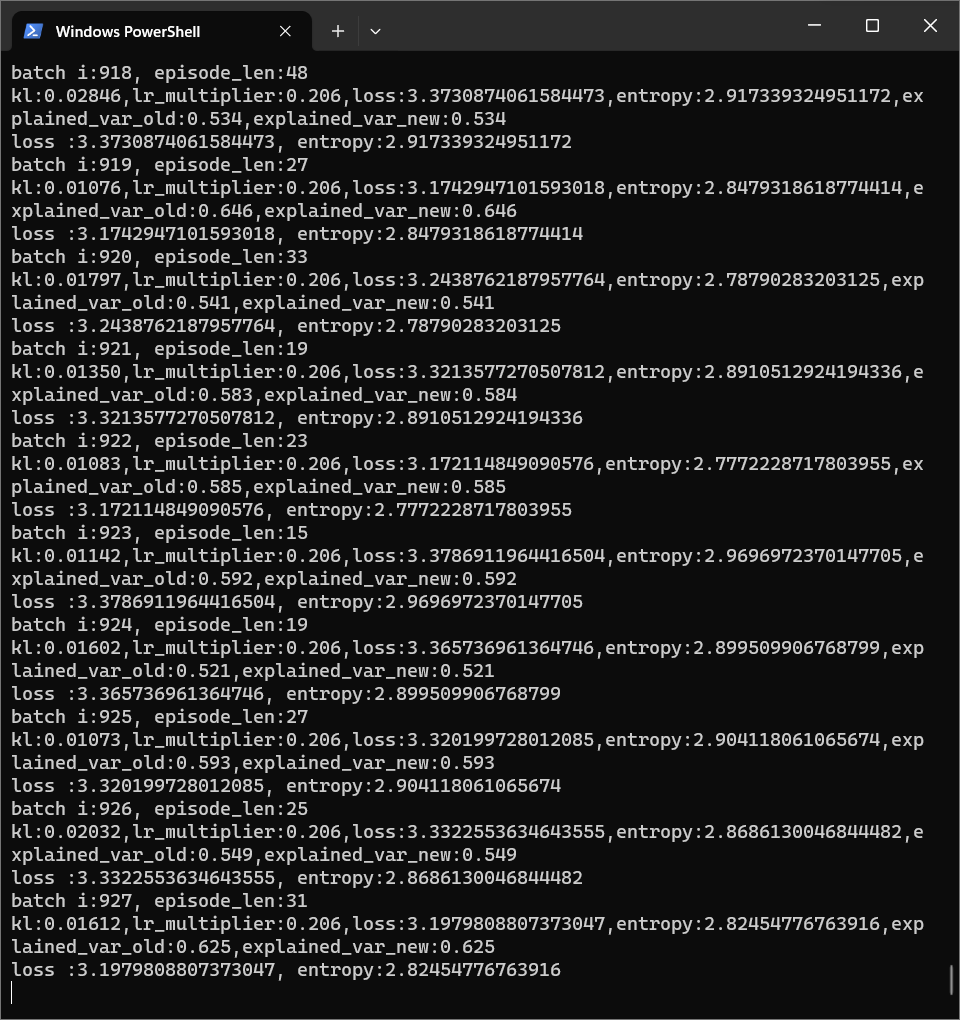
改用cpu进行训练,实测训练速度和使用colab的Tesla_T4速度相近,大概两分钟一代。
-
15*15棋盘实际训练进度较慢,引用junxiaosong的Tips for training:
It is good to start with a 6 * 6 board and 4 in a row. For this case, we may obtain a reasonably good model within 500~1000 self-play games in about 2 hours.
For the case of 8 * 8 board and 5 in a row, it may need 2000~3000 self-play games to get a good model, and it may take about 2 days on a single PC.